30天学会Python编程:14.Python文件与IO操作编程指南
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
|
模式组合示例:
基本原则:
# 读取操作
file.read(size) # 读取size字节内容,省略size则读取全部
file.readline() # 读取一行,包括换行符
file.readlines() # 读取所有行到列表
# 写入操作
file.write(string) # 写入字符串
file.writelines(seq) # 写入字符串序列
# 指针操作
file.seek(offset, whence=0) # 移动文件指针
file.tell() # 返回当前指针位置
操作技巧:
read(size)分块读取,避免内存溢出readline()seek()flush()可强制将缓冲区数据写入磁盘# 传统安全写法
try:
f = open('data.txt', 'r', encoding='utf-8')
content = f.read()
# 处理内容
finally:
f.close() # 确保文件关闭
# 现代推荐写法(上下文管理器)
with open('data.txt', 'r', encoding='utf-8') as f:
for line in f: # 逐行迭代,内存高效
process_line(line.strip())
要点说明:
# 高效文件复制
defcopy_file(source, destination, buffer_size=1024*1024): # 1MB缓冲区
withopen(source, 'rb') as src, open(destination, 'wb') as dst:
whileTrue:
chunk = src.read(buffer_size)
ifnot chunk:
break
dst.write(chunk)
# 修改二进制文件特定位置
withopen('binary.dat', 'r+b') as f: # 读写二进制模式
f.seek(10) # 定位到第10字节
f.write(b'\x41\x42') # 写入AB
二进制操作要点:
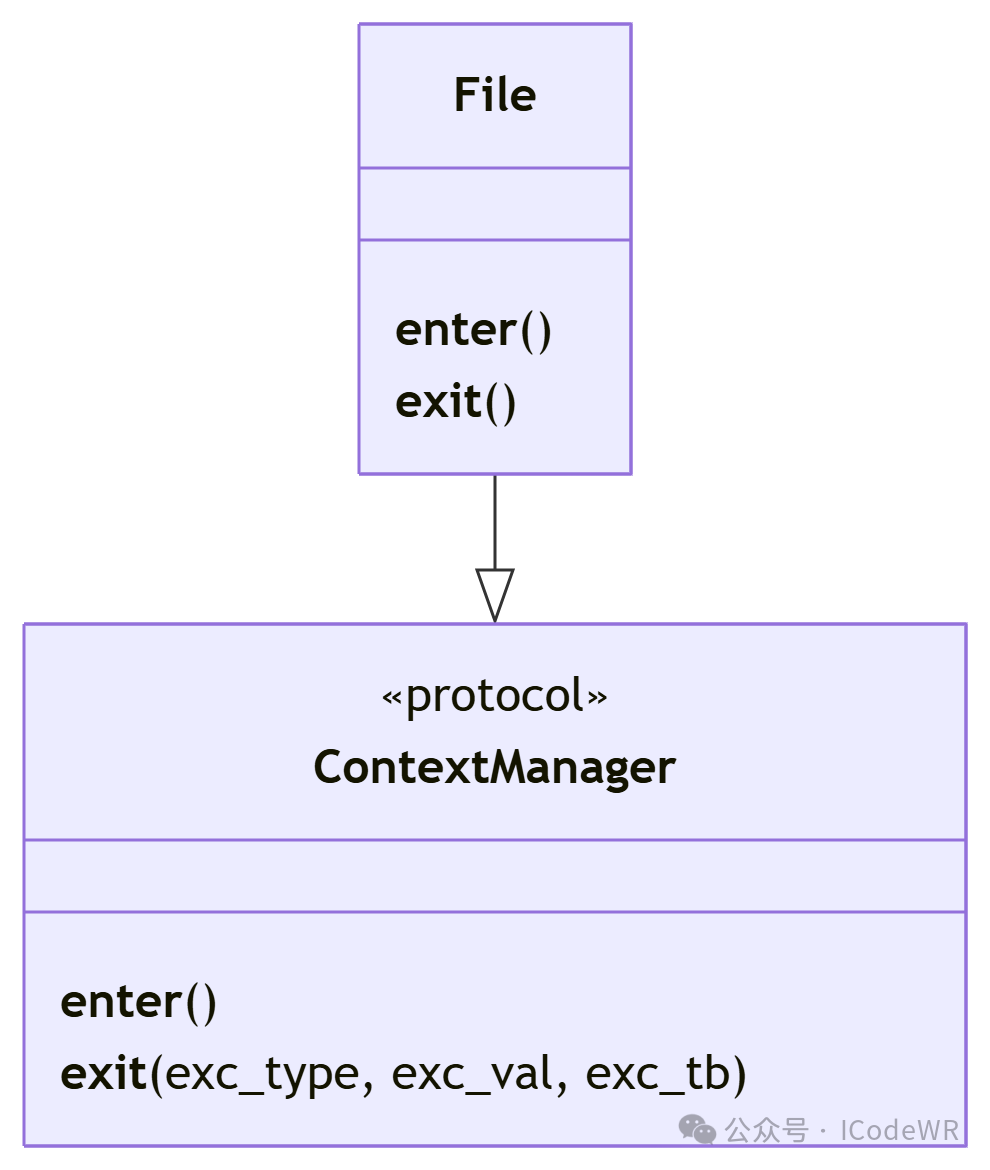
上下文管理器协议:
__enter__():进入上下文时调用,返回资源对象__exit__():退出上下文时调用,处理清理和异常class ManagedResource:
"""资源管理上下文示例"""
def__init__(self, name):
self.name = name
self.resource = None
def__enter__(self):
print(f"初始化 {self.name} 资源")
self.resource = open(self.name, 'a+', encoding='utf-8')
returnself.resource
def__exit__(self, exc_type, exc_val, exc_tb):
print(f"清理 {self.name} 资源")
ifself.resource:
self.resource.close()
if exc_type:
print(f"资源操作异常: {exc_val}")
returnTrue# 抑制异常传播
# 使用示例
with ManagedResource('data.log') as res:
res.write("2023-01-01 INFO: Application started\n")
# 模拟异常: res.undefined_method()
自定义上下文应用场景举例:
import csv
# 安全读取CSV(处理各种格式问题)
defread_csv_safely(file_path):
withopen(file_path, 'r', encoding='utf-8', newline='') as f:
# 自动检测方言格式
dialect = csv.Sniffer().sniff(f.read(1024))
f.seek(0)
reader = csv.reader(f, dialect)
# 处理BOM(字节顺序标记)
if reader[0][0].startswith('\ufeff'):
reader[0][0] = reader[0][0][1:]
returnlist(reader)
# 字典写入CSV(处理特殊字符)
defwrite_dict_csv(data, file_path):
withopen(file_path, 'w', encoding='utf-8', newline='') as f:
# 自动获取字段名
fieldnames = data[0].keys() if data else []
writer = csv.DictWriter(f, fieldnames=fieldnames,
quoting=csv.QUOTE_NONNUMERIC)
writer.writeheader()
for row in data:
# 转义换行符等特殊字符
cleaned_row = {k: str(v).replace('\n', '\\n') for k, v in row.items()}
writer.writerow(cleaned_row)
CSV处理建议:
newline=''避免Windows换行问题csv.DictReader/DictWriter提高可读性import json
from datetime import datetime
# 自定义JSON编码器(处理日期等特殊类型)
classCustomEncoder(json.JSONEncoder):
defdefault(self, obj):
ifisinstance(obj, datetime):
return obj.isoformat()
ifisinstance(obj, set):
returnlist(obj)
returnsuper().default(obj)
# 安全写入JSON
defwrite_json(data, file_path, indent=2):
withopen(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, cls=CustomEncoder, indent=indent, ensure_ascii=False)
# 流式读取大JSON文件
defstream_large_json(file_path):
withopen(file_path, 'r', encoding='utf-8') as f:
# 使用ijson库处理大文件更佳
for line in f:
# 简单逐行处理(实际JSON可能跨行)
if line.strip():
try:
yield json.loads(line)
except json.JSONDecodeError:
continue
JSON处理技巧:
ensure_ascii=False保存非ASCII字符python -m json.tool data.jsonimport configparser
# 创建多段配置
config = configparser.ConfigParser()
config['DEFAULT'] = {
'debug': 'False',
'log_level': 'INFO'
}
config['DATABASE'] = {
'host': 'localhost',
'port': '5432',
'username': 'admin'
}
# 安全写入配置
withopen('app_config.ini', 'w', encoding='utf-8') as f:
config.write(f)
# 类型安全的配置读取
defget_config(config_path, section, option, dtype=str, default=None):
config = configparser.ConfigParser()
config.read(config_path, encoding='utf-8')
try:
if dtype == bool:
return config.getboolean(section, option)
elif dtype == int:
return config.getint(section, option)
elif dtype == float:
return config.getfloat(section, option)
else:
return config.get(section, option)
except (configparser.NoSectionError, configparser.NoOptionError):
return default
配置文件实践建议:
import os
import shutil
# 安全创建目录
defsafe_makedirs(path):
"""递归创建目录,忽略已存在错误"""
try:
os.makedirs(path, exist_ok=True)
except OSError as e:
ifnot os.path.isdir(path):
raise
# 递归复制目录
defcopy_directory(src, dst):
"""复制目录结构及文件"""
ifnot os.path.exists(dst):
os.makedirs(dst)
for item in os.listdir(src):
s = os.path.join(src, item)
d = os.path.join(dst, item)
if os.path.isdir(s):
copy_directory(s, d)
else:
shutil.copy2(s, d) # 保留元数据
from pathlib import Path
import time
# 创建项目目录结构
project = Path('my_project')
(project / 'src').mkdir(parents=True, exist_ok=True)
(project / 'tests').mkdir(exist_ok=True)
(project / 'data/raw').mkdir(parents=True, exist_ok=True)
# 文件操作链式调用
readme = project / 'README.md'
readme.write_text('# My Project\n', encoding='utf-8')
# 筛选特定文件
py_files = [f for f in project.rglob('*.py')
if f.stat().st_size > 1024and
time.time() - f.stat().st_mtime < 86400]
# 路径安全操作
defsafe_rename(src, dst):
"""安全重命名,防止覆盖"""
src_path = Path(src)
dst_path = Path(dst)
if dst_path.exists():
raise FileExistsError(f"目标文件已存在: {dst}")
src_path.rename(dst_path)
pathlib优势:
from io import StringIO, BytesIO
import pandas as pd
# 文本内存文件
text_stream = StringIO()
text_stream.write("姓名,年龄\n")
text_stream.write("张三,25\n")
text_stream.write("李四,30\n")
# 从内存读取CSV
text_stream.seek(0) # 重置指针
df = pd.read_csv(text_stream)
print(df)
# 二进制内存文件
image_data = BytesIO()
withopen('photo.jpg', 'rb') as f:
image_data.write(f.read())
# 修改内存中的图像
from PIL import Image
image_data.seek(0)
img = Image.open(image_data)
img = img.rotate(45) # 旋转45度
img.save('rotated.jpg')
内存文件应用场景举例:
import pickle
import shelve
# 安全pickle操作
defsafe_pickle_dump(obj, file_path):
"""限制反序列化时的对象创建"""
withopen(file_path, 'wb') as f:
pickler = pickle.Pickler(f)
pickler.dispatch_table = copyreg.dispatch_table.copy()
# 限制可序列化的类
pickler.dispatch_table[MyClass] = MyClass.__reduce__
pickler.dump(obj)
# 使用shelve持久化对象
defsave_to_shelf(data_dict, shelf_path):
with shelve.open(shelf_path, 'c') as db:
for key, value in data_dict.items():
db[key] = value
# 大对象序列化优化
classLargeData:
def__init__(self, data_generator):
self.data = data_generator
def__getstate__(self):
# 流式处理大对象
return {'chunks': list(self.data)}
def__setstate__(self, state):
self.data = iter(state['chunks'])
序列化建议:
__reduce__方法控制对象重建import time
from pathlib import Path
import re
classLogMonitor:
def__init__(self, log_path, patterns=None):
self.log_path = Path(log_path)
self.patterns = patterns or {
'ERROR': re.compile(r'ERROR: (.+)'),
'WARNING': re.compile(r'WARN: (.+)')
}
self.position = 0
self.stats = {level: 0for level inself.patterns}
defstart_monitoring(self, interval=1.0):
"""监控日志文件变化"""
print(f"开始监控日志: {self.log_path}")
try:
whileTrue:
self.check_updates()
time.sleep(interval)
except KeyboardInterrupt:
print("\n监控终止")
defcheck_updates(self):
"""检查日志更新并处理新内容"""
ifnotself.log_path.exists():
return
withself.log_path.open('r', encoding='utf-8') as f:
# 定位到上次读取位置
f.seek(self.position)
# 处理新内容
for line in f:
self.process_line(line)
# 更新读取位置
self.position = f.tell()
defprocess_line(self, line):
"""处理单行日志"""
for level, pattern inself.patterns.items():
match = pattern.search(line)
ifmatch:
self.stats[level] += 1
print(f"检测到 {level}: {match.group(1)}")
# 触发警报或其他操作
if level == 'ERROR':
self.trigger_alert(match.group(1))
deftrigger_alert(self, error_msg):
"""触发错误警报"""
# 实际应用中可发送邮件、Slack消息等
print(f"!!! 严重错误警报: {error_msg} !!!")
defget_stats(self):
returnself.stats.copy()
# 使用示例
if __name__ == "__main__":
monitor = LogMonitor('application.log')
monitor.start_monitoring()
import hashlib
import shutil
from pathlib import Path
classFileSynchronizer:
def__init__(self, source, destination):
self.source = Path(source)
self.destination = Path(destination)
defsync(self):
"""执行同步操作"""
# 确保目标目录存在
self.destination.mkdir(parents=True, exist_ok=True)
# 遍历源目录
for src_path inself.source.rglob('*'):
if src_path.is_dir():
continue
rel_path = src_path.relative_to(self.source)
dst_path = self.destination / rel_path
# 判断是否需要同步
ifself.need_sync(src_path, dst_path):
self.copy_file(src_path, dst_path)
defneed_sync(self, src, dst):
"""判断文件是否需要同步"""
ifnot dst.exists():
returnTrue
# 比较修改时间和大小
src_stat = src.stat()
dst_stat = dst.stat()
# 修改时间不同或大小不同
if src_stat.st_mtime > dst_stat.st_mtime or \
src_stat.st_size != dst_stat.st_size:
returnTrue
# 校验和验证
returnself.file_hash(src) != self.file_hash(dst)
deffile_hash(self, path, algorithm='sha256', chunk_size=8192):
"""计算文件哈希值"""
h = hashlib.new(algorithm)
with path.open('rb') as f:
while chunk := f.read(chunk_size):
h.update(chunk)
return h.hexdigest()
defcopy_file(self, src, dst):
"""复制文件并保留元数据"""
print(f"同步: {src} -> {dst}")
dst.parent.mkdir(parents=True, exist_ok=True)
shutil.copy2(src, dst) # 保留元数据
# 使用示例
if __name__ == "__main__":
syncer = FileSynchronizer('source_folder', 'backup_folder')
syncer.sync()
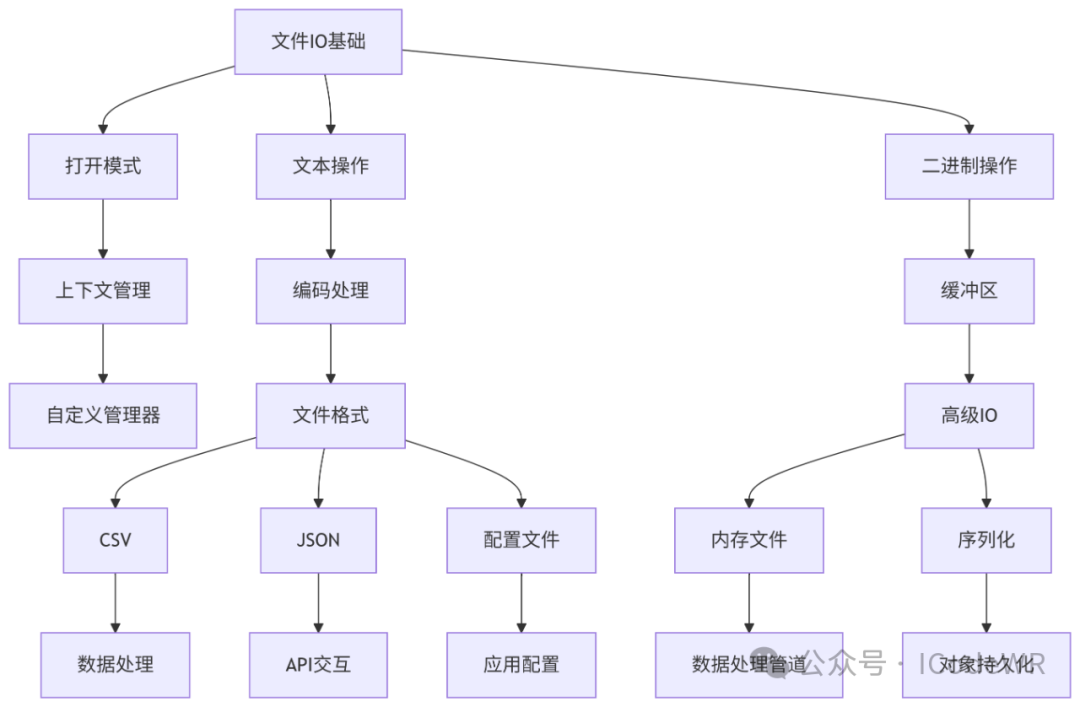
Python文件IO操作是开发中的基础能力,掌握本文内容后,我们应该能够:
持续学习建议:
通过不断实践和探索,我们将能够应对各种复杂的文件处理场景,构建健壮高效的应用程序。
阅读原文:原文链接






 400 186 1886
400 186 1886