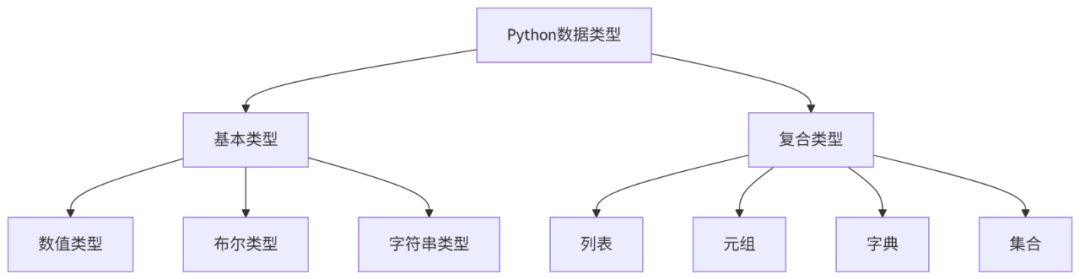
30天学会Python编程:3. Python数据类型详解
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
|
特性:
操作示例:
num = 123_456_789 # 使用下划线提高可读性
binary = 0b1010 # 二进制 10
hex_num = 0xFF # 十六进制 255
# 类型转换
int("42") # 字符串转整数
int(3.99) # 浮点数转整数(截断)
特性:
科学计数法:
a = 1.23e-5 # 0.0000123
b = 2.5e6 # 2500000.0
精确计算建议:
from decimal import Decimal
print(Decimal('0.1') + Decimal('0.2')) # 精确计算
c = 3 + 4j
print(c.real) # 实部 3.0
print(c.imag) # 虚部 4.0
print(c.conjugate()) # 共轭复数 (3-4j)
is_active = True
is_admin = False
# 逻辑运算
print(True and False) # False
print(True or False) # True
print(not True) # False
真值测试规则:
应用示例:
name = ""
if not name:
print("姓名不能为空")
s1 = '单引号'
s2 = "双引号"
s3 = """多行
字符串"""
s4 = r"原始字符串\n不转义" # raw string
索引与切片:
text = "Python"
print(text[0]) # 'P' (正向索引)
print(text[-1]) # 'n' (负向索引)
print(text[1:4]) # 'yth' (切片)
常用方法:
# 字符串方法链式调用
result = " Hello World! ".strip().lower().replace("world", "Python")
print(result) # "hello python!"
格式化方法:
# f-string (Python 3.6+)
name = "Alice"
print(f"Hello, {name}!")
# format方法
print("{} is {} years old".format(name, 25))
特性:
操作示例:
# 列表创建
nums = [1, 2, 3, 2]
mixed = [1, "a", True, [2, 3]]
# 常用操作
nums.append(4) # 追加元素
nums.insert(1, 1.5) # 插入元素
nums.remove(2) # 删除第一个匹配项
nums.pop() # 移除并返回最后一个元素
特性:
特殊语法:
single = (1,) # 单元素元组必须有逗号
empty = () # 空元组
a, b = (1, 2) # 元组解包
特性:
操作示例:
# 字典创建
person = {"name": "Alice", "age": 25}
scores = dict(math=90, physics=85)
# 常用操作
person["email"] = "alice@example.com" # 添加/修改
age = person.get("age", 0) # 安全获取
for key, value in person.items(): # 遍历
print(f"{key}: {value}")
特性:
操作示例:
a = {1, 2, 3}
b = {2, 3, 4}
# 集合运算
print(a | b) # 并集 {1, 2, 3, 4}
print(a & b) # 交集 {2, 3}
print(a - b) # 差集 {1}
int("123") # 字符串→整数
float("3.14") # 字符串→浮点数
str(100) # 数字→字符串
list("abc") # 字符串→列表 ['a', 'b', 'c']
tuple([1,2,3]) # 列表→元组 (1, 2, 3)
set([1,2,2,3]) # 列表→集合 {1, 2, 3}
type(123) is int # 类型检查
isinstance("hello", str) # 更推荐的检查方式
issubclass(bool, int) # 检查继承关系 (在Python中bool是int的子类)
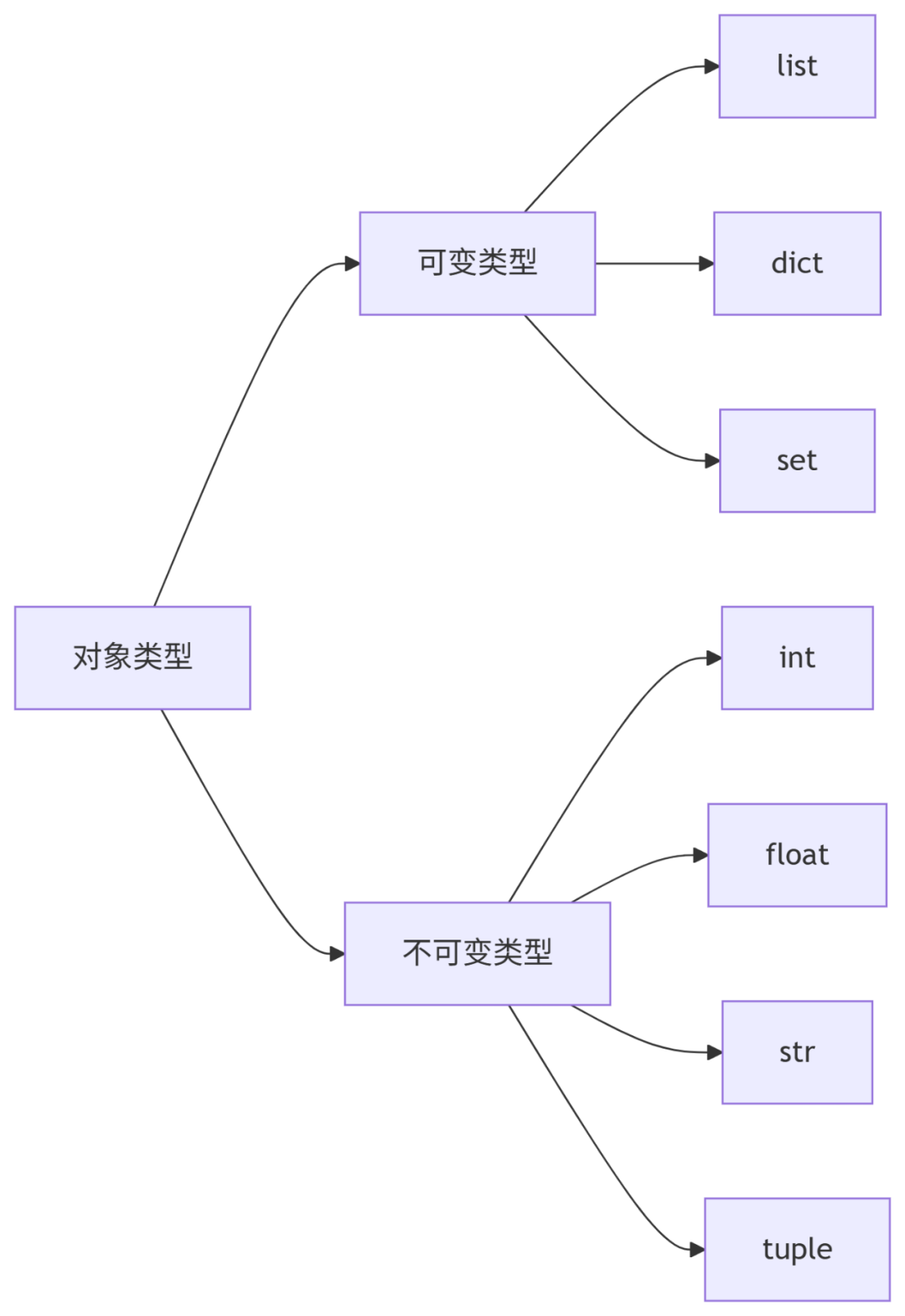
不可变对象示例:
a = "Hello"
b = a
a += " World"
print(a) # "Hello World"
print(b) # "Hello" (b未改变)
可变对象示例:
lst1 = [1, 2, 3]
lst2 = lst1
lst1.append(4)
print(lst2) # [1, 2, 3, 4] (lst2也被修改)
# 学生成绩处理系统
students = [
{"name": "Alice", "scores": [85, 90, 78]},
{"name": "Bob", "scores": [92, 88, 95]},
{"name": "Charlie", "scores": [78, 80, 82]}
]
# 计算平均分
for student in students:
scores = student["scores"]
avg = sum(scores) / len(scores)
student["average"] = round(avg, 2) # 保留两位小数
# 按平均分排序
sorted_students = sorted(students,
key=lambda x: x["average"],
reverse=True)
# 输出结果
for i, student inenumerate(sorted_students, 1):
print(f"{i}. {student['name']}: {student['average']}")
def word_frequency(text):
"""统计文本中单词出现频率
Args:
text (str): 输入文本
Returns:
dict: 单词到频率的映射
"""
words = text.lower().split()
freq = {}
for word in words:
# 去除标点符号
word = word.strip(".,!?")
if word:
freq[word] = freq.get(word, 0) + 1
return freq
text = "Hello world. Hello Python. Python is great!"
print(word_frequency(text))
# 输出:{'hello': 2, 'world': 1, 'python': 2, 'is': 1, 'great': 1}
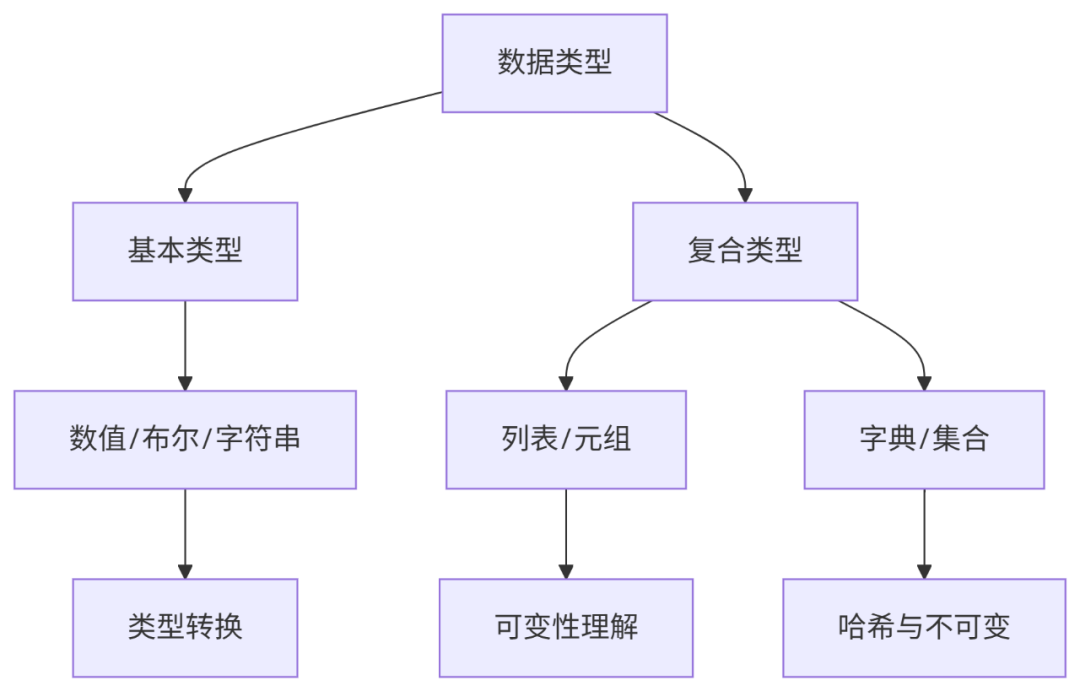
核心要点:
实践建议:
进阶方向:
常见陷阱:
阅读原文:原文链接






 400 186 1886
400 186 1886